
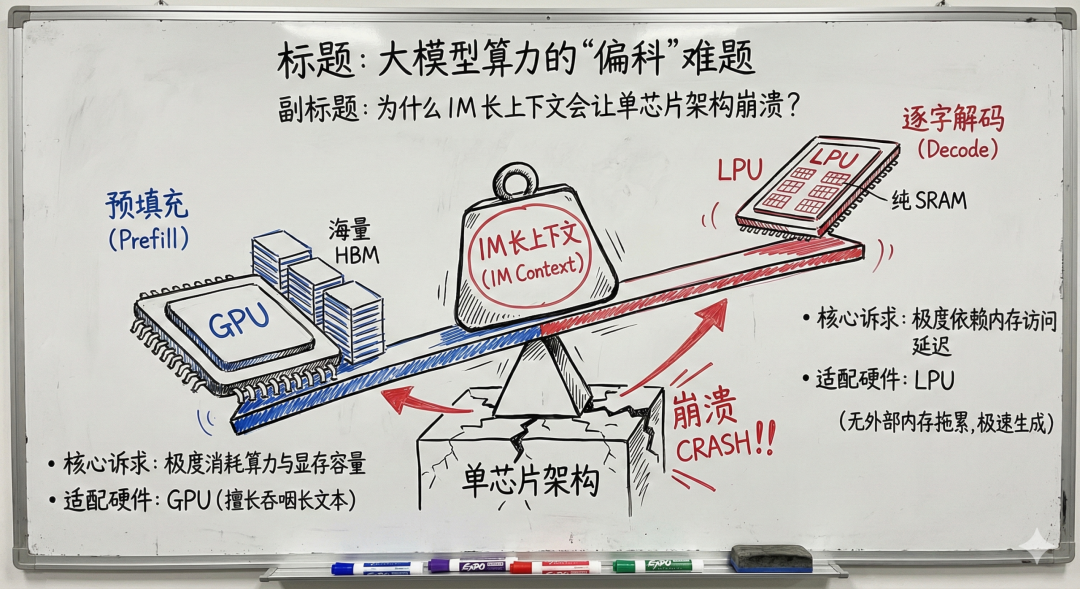
在处理 100K 甚至 1M 超长上下文时,AI 算力面临一个明显的偏科问题:
- 处理输入的预填充 (Prefill) 阶段,消耗巨大的浮点算力和显存容量
- 生成输出的解码 (Decode) 阶段,依赖极低的内存延迟
目前没有任何单一架构能同时处理好这两件事。
一、分离式架构 (PD Disaggregation):让合适的芯片做擅长的事
既然没有完美的单芯片,那就用架构来弥补。业界正转向跨硬件的异构协同:
- 重型算力处理重型计算:让拥有海量高带宽内存 (HBM) 的 GPU 阵列负责批量处理长文本,生成数十 GB 的 KV Cache
- 极速缓存处理生成延迟:让抛弃片外内存、采用纯 SRAM 的 Groq LPU 接管后续解码任务,以纳秒级延迟逐字输出
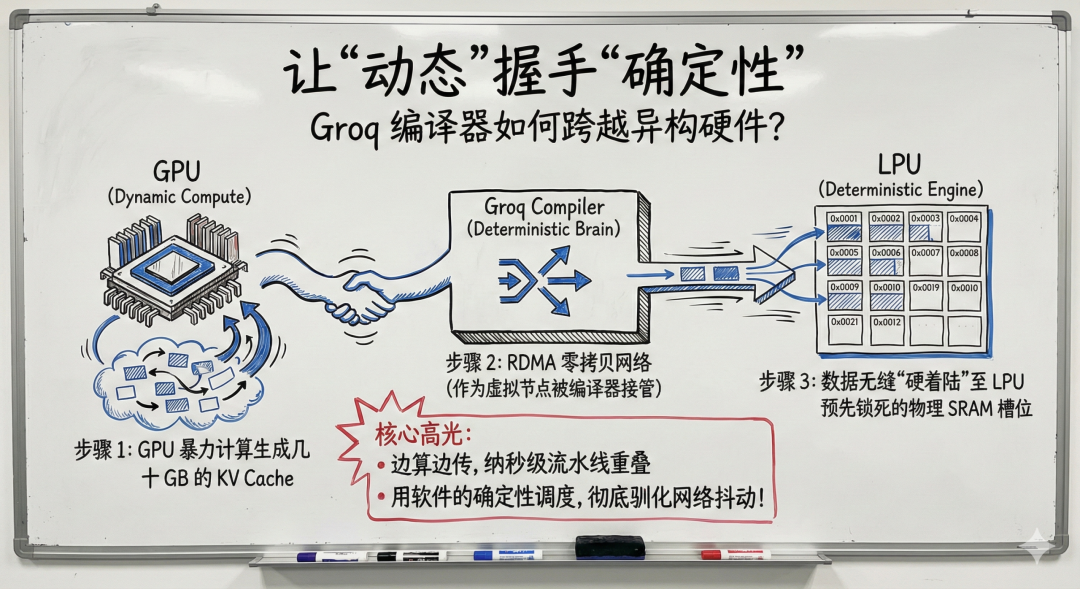
二、编译器:用确定性驯服动态网络
GPU 与 LPU 的结合不止是拉一根网线。GPU 的运算是动态的,而 LPU 需要绝对精确的周期对齐。数据涌入控制不好,LPU 极小的 SRAM 就会被撑爆。
这里的关键在编译器的拓扑扩展。Groq 的编译器将物理网卡视为一个带有已知延迟的虚拟节点,通过静态内存分配和 RDMA 零拷贝,让 GPU 端生成的数据直接穿透网络,落入 LPU 预先锁定的物理 SRAM 槽位。边算边传,靠纳秒级流水线重叠和边缘 FIFO 队列,把外部不可控的网络抖动转化为内部可控的确定性数据流。
三、TGV 加持的 CoPoS 面板级封装
软件优化只在传输层解决问题。TGV (玻璃通孔) 加持的 CoPoS 面板级封装,把距离问题从物理层面直接消灭。
突破晶圆尺寸限制
传统硅基 CoWoS 封装受限于 12 英寸圆形晶圆的物理边界。CoPoS 用 500mm 以上的大尺寸矩形玻璃面板替代硅片。GPU 芯粒、LPU 芯粒、HBM 和 SRAM 可以全部高密度封装在同一个模块内部。原本需要机柜级部署的异构系统,被微缩到一块基板上。
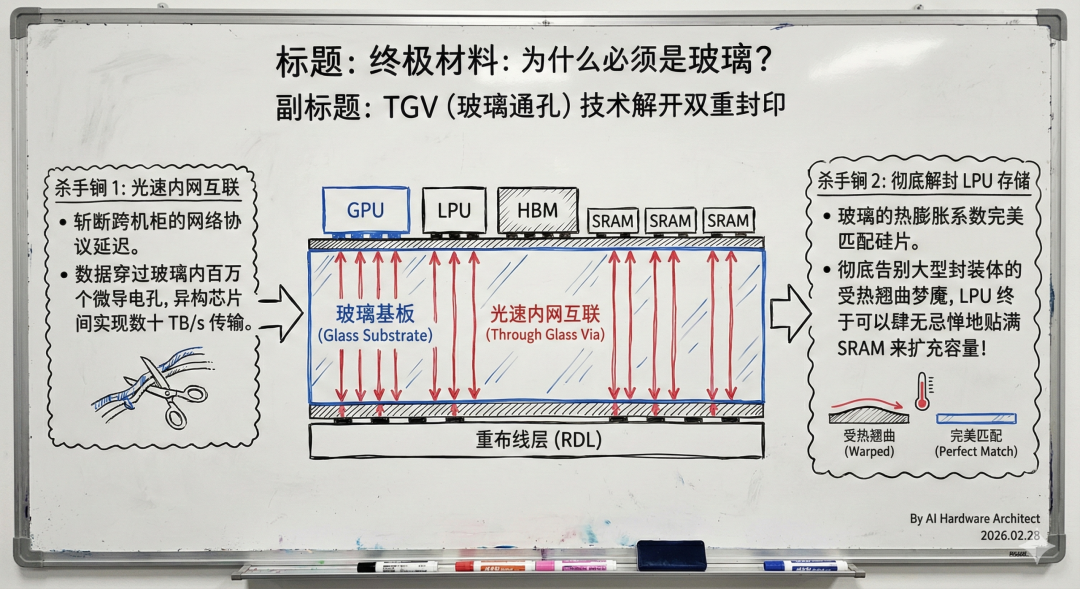
互联带宽与存储扩展
玻璃基板的电介质特性配合内部数百万 TGV 微孔,消灭了跨设备传输的网络协议延迟。GPU 与 LPU 之间的数据转移带宽可达数十 TB/s。更重要的是,玻璃与硅的热膨胀系数匹配,让 LPU 封装体内可以贴满 SRAM 存储芯粒来扩展容量,不至于因热翘曲失效。
总结
大模型推理硬件的未来,不止是先进制程的堆叠。跨异构架构的编译器作为软件大脑,配合玻璃基板与先进封装的物理骨架,在一块面板上同时实现高吞吐与低延迟,这个方向正在接近落地。